Tech Blog
NLP techniques: Semi-supervised topic modelling
As companies increasingly collect large amounts of data on everything from customer engagement to field reports, many organisations grapple with the same question every day: how can we gather relevant insights from a large collection of text data?
One way of course would be to simply go and read all the documents and summarise our findings, but this could take ages. Imagine the human power needed to manually keep up to date with all the articles appearing in, say, PubMed Central, the online database for biomedical literature. Hosting millions of publications, and with more than a thousand new submissions per day, it’s virtually impossible to manage this massive collection of articles in a reasonable time without automation.
What is topic modelling?
Topic modelling is a branch of natural language processing that aims to extract a relatively small number of topics from a corpus (or collection of articles), in a (typically) unsupervised manner. The central idea that underpins topic modelling is that an individual article consists of multiple topics, and that these topics are present in all articles, albeit in different proportions.
Describing a text dataset in terms of a moderate number of topics that permeate throughout the corpus is a useful representation. The extracted topics could allow one to, at a glance, obtain a rich characterisation of the entire collection of text data. More practically, this analysis allows us to identify similar articles based on the topics they cover, or even the possibility to search for content by topic as opposed to simply a keyword search.
Latent Dirichlet Allocation (LDA) and the drawbacks of unsupervised topic modelling
Up to now, the notion of a topic has been pretty abstract. Topic modelling formalises topics as probability distributions over the vocabulary (the words in the corpus).
Latent Dirichlet Allocation (LDA), almost synonymous with topic modelling, is the dominant method in this field. Developed in 2003 by Blei et al, it postulates a generative model for how a topic gives rise to the words in a document. We won’t go into the details here because it is covered extensively in many other sources, but essentially it assumes two things:
- That each topic is a distribution over words and
- That each document is a distribution of topics, i.e. every word in a document is generated by first sampling a topic and then sampling from the selected topic’s word distribution.
Given this probabilistic model of the probabilistic model p(data|topics), the actual LDA algorithm then tries to determine the posterior p(topics|data); the authors show this can be solved with tools from variational inference.
While LDA makes assumptions about the generative process and the form of the probability distributions (i.e. Dirichlet priors), it has proven itself to be a very successful method for extracting topics. It has also served as a springboard for many, many derived topic models which aim to extend LDA to related situations. Notable examples include “dynamic topic modelling”, which models the evolution of topics through time, or “correlated topic modelling”, which acknowledges that some topics may be correlated with one another.
However, one key drawback of LDA is that it is unsupervised and this can result in unsatisfactory topics. For example, emerging areas of research in Medline might not be identified as a topic by vanilla LDA, simply because there aren’t many articles on the subject. We might think that re-running with an increased number of topics (a hyperparameter) might force topics to break apart into narrower themes and eventually produce results that indicate the new research area has a topic of its own. In practice however, it has been observed that, with LDA, underrepresented topics tend to be washed out by ones that have a stronger presence in the corpus.
Semi-supervised topic modelling
To get around this difficulty, semi-supervised topic modelling allows the user to inject prior knowledge into the topic model. In particular, there are versions where the user can supply the model with topic “seed” words, and the model algorithm then encourages topics to be built around these seed words. This not only resolves the issue illustrated above (the absence of known topics), but more broadly gives us the flexibility to steer topics towards relevant themes by simply adding keywords, whilst also leaving room to uncover “unknown” topics.
Research in this area is scant but there are two algorithms that tackle the problem head on. The first is a variant of LDA called SeededLDA, where the LDA algorithm is augmented so that the topic-word and topic-document distributions take account of the seed words.
The second is called anchored CorEx (short for “correlation explanation”), which implements a completely novel approach to topic modelling compared to LDA. Unlike LDA, CorEx makes no assumption about the data generation process, instead approaching topic modelling in an information theoretic manner. CorEx treats each word as a random variable and seeks to find collections of words (i.e. topics) that best “explain” the data. Explaining translates into decorrelating the observed word count data, which proceeds by optimizing a mutual information based objective function. The authors observe that this objective function realises an information bottleneck and this can be exploited to modify the model to accept seed, or “anchor”, words as input.
The flexibility of anchor word selection is a great feature of this model. Anchor words can be grouped together in any way, they can be given different weights (a model hyperparameter) and interestingly the same anchor words applied to multiple topics can be used to uncover topic “aspects”. The original paper provides an example where a CorEx model with 55 topics in total is fitted, but five of these topics are equally anchored with the words “protest” and “protests”. The model then uncovers topics that tease apart five different aspects of protests, shown below for convenience.
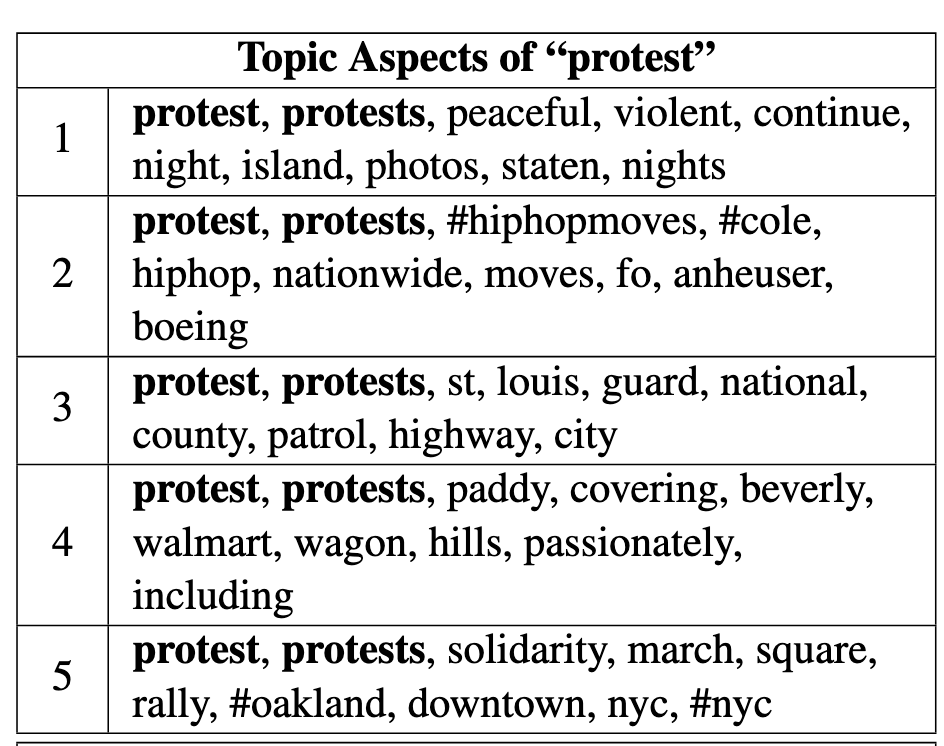
Topic aspects around “protest” and “riot” from running a CorEx topic model with 55 topics and anchoring “protest” and “protests” together to five topics and “riot” and “riots” together to five topics with β = 2. Anchor words are shown in bold. Note, topics are not ordered by total correlation. Source: Gallagher, Reing, Kale and Ver Steeg
To summarise, when faced with a situation where we wish to uncover topics in text data but have knowledge about what words we want to base some of these topics, then semi-supervised topic modelling can help. This setup can help to uncover underrepresented topics, or improve the relevance of topics over the unsupervised case.